
By DAVID SHAYWITZ MD
At long last, we seem to be on the threshold of departing the earliest phases of AI, defined by the always tedious “will AI replace doctors/drug developers/occupation X?” discussion, and are poised to enter the more considered conversation of “Where will AI be useful?” and “What are the key barriers to implementation?”
As I’ve watched this evolution in both drug discovery and medicine, I’ve come to appreciate that in addition to the many technical barriers often considered, there’s a critical conceptual barrier as well – the threat some AI-based approaches can pose to our “explanatory models” (a construct developed by physician-anthropologist Arthur Kleinman, and nicely explained by Dr. Namratha Kandula here): our need to ground so much of our thinking in models that mechanistically connect tangible observation and outcome. In contrast, AI relates often imperceptible observations to outcome in a fashion that’s unapologetically oblivious to mechanism, which challenges physicians and drug developers by explicitly severing utility from foundational scientific understanding.
Implementing AI, Part 1: Why Doctors Aren’t Biting
A physician examines her patient and tries to integrate her observations – what she sees, feels, hears, and is told – and what she learns from laboratory and radiological tests – sodium level, CT scans – to formulate an understanding of what’s wrong with her patient, and to fashion a treatment approach. The idea is that this process of understanding of what’s wrong and developing a therapeutic plan is fundamentally rooted in science. Science is the Rosetta Stone that allows us to relate symptoms to disease, and disease to treatment.
The premise that medicine is driven by science is deeply ingrained in the contemporary history of medicine and also (not coincidentally) in the education of physicians; it’s why pre-medical students are compelled to master the basics of chemistry, biology, and physics, for example. Scientific underpinnings are continuously reinforced – I often think of this example from my training: as a medical student, after I asked a resident why a particular patient had atrial fibrillation (AF), I was immediately quizzed, “Why do you think, on first principals, someone would have AF? Think it through.” The idea was that you could use scientific logic to deduce the causes of this condition.
In fact, the way everyone actually thought about AF was by memorizing a mnemonic (“PIRATES”) that lists the major causes of AF based on empiric observation, but the conceit was you could derive them from scratch using the basic principles of physics, biology, and chemistry.
Over time, I came to appreciate how much of medicine wasn’t so much science as scientism masquerading as science — kosher-style rather than kosher. We describe phenomena using science, which gives us a sense of understanding and structure – yet we often lack actual understanding about what we’re observing, or why our treatments work. We have scientific explanations that may appear solid at first glance, but are flimsy upon closer inspection. More commonly, I imagine, we rely on scientific explanations as heuristics to enable us to get through our days, as a scaffold upon which to organize our information.
I suspect AI is viscerally uncomfortable, and challenging to apply to clinical care or drug discovery (see part 2), because of the psychological importance and cultural engraining of our science-based explanatory models. At a high level, as Erik Reinertsen (a talented MD/PhD student at Emory and Georgia Tech with an expertise in data science, who’s spending several months with our team) has patiently explained to me, “machine learning (a common type of AI) integrates individually weak signals (often many, imperceptible signals) as input to perform classification or prediction (disease/no disease; binding/no binding etc).” (See Figure.)
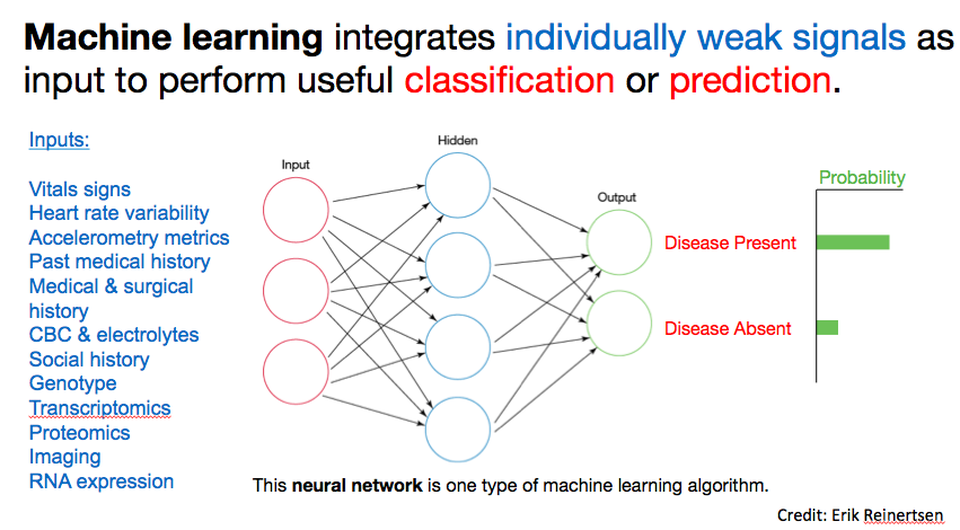
Two critical aspects warrant further discussion. First, the idea of extracting utility from multiple, possibly imperceptible signals vs several obvious ones is a really difficult concept to grapple with because, by its very nature, you can’t see or come up with a mental model for what’s driving the conclusion. We rely on mental models to identify factors driving conclusions, yet in the AI scenario, such a model is generally not required. Rather, what matters is an ensemble of tiny signals you’d likely perceive as noise, and yet collectively they are, apparently, significant. Second, AI approaches correlate observations with results – they do not explain the relationship in a way we would call “mechanistic.” This aspect is often deeply uncomfortable for physicians, drug developers, and other practitioners who are driven by a belief in, and thirst for, an underlying explanation.
The indifference to mechanistic explanation can (and has) led to some very silly results in AI, as the strongest correlations are often artifacts such as batch effects, lab effects, or meta-phenomena. For instance, Isaac Kohane’s group at Harvard reported a correlation between 4am white blood counts data results and bad outcomes – reflecting not underlying circadian physiology but rather the likely grim clinical scenario associated with a 4am blood draw.
While these mistakes are amusing, they don’t invalidate the potential utility underlying technique. Our most substantial challenge, I expect, will be figuring out how to wrap our heads around the core premise of AI – are we, as physicians, ready to receive and act on answers without even the pretense of explanation? Practitioners of disciplines built on an edifice of rational explanations – including medicine and drug discovery – will struggle mightily to accept empirical data that can’t be seen to reach conclusions that can’t be rationalized.
Consider the topic of predicting cardiovascular risk. Over time, we’ve grown comfortable with established risk factors such as cholesterol level, diabetes, smoking, hypertension, etc, and I suspect most doctors have a mental image (not necessarily accurate) of how each of these discrete factors contribute scientifically to the risk of disease. But then along comes Sek Kathiresan, and offers a novel test, a multi-gene signature (discussed on our Tech Tonics podcast here) that computes a risk score based on thousands of variants. How do you even begin to get your head around that? To help, Kathiresan translates the risk onto a 0-10 scale, so you can at least dimensionalize it. I suspect most doctors will still struggle to incorporate this information into their explanatory models of disease. Perhaps for many, bucketing it as “genetic risk” will suffice.
If the rise of algorithms is inevitable, scores like Kathiresan’s will be the rule, rather than the exception. Doctors, other caregivers, and patients will receive all sorts of information about risk that they’ll be asked to accept, but not intuitively understand. Health assessments presented in the form of hermetic actuality table data – your risk of [condition A] is [B%] — will be difficult to manage, especially when we’re not able to offer any mechanistic sort of explanation; you may not even be able to determine exactly which data led to the conclusion.
Yet, this inability to mechanistically explain a prediction may not be as far removed from modern medicine as we suppose. Consider an area we often associate with the apotheosis of modern medicine, linking individual genes to specific phenotypes. In practice, determining the role of even single genes in disease can be surprisingly complicated. For example, a fascinating study of a population with high levels of consanguinity demonstrated that genes previously thought to be definitively associated with phenotypes such as hearing loss were actually not; some individuals lacking a single functional copy of a suspicious gene could nevertheless hear just fine. Multiple examples from the world of rare diseases demonstrate that conditions that initially seem to be defined by specific genetic mutations can nevertheless exhibit remarkable variability in phenotype, at both the molecular and the organismic level. If mechanistic explanation can be tricky for these so-called “single gene” conditions, imagine the true complexity that presumably underlies diseases such as diabetes and schizophrenia.
The bottom line is that physicians tend to maintain science-based heuristics in their heads, informing how they think about the manifestation of disease and their conceptualization of treatments. This represents a bit of a charade, or self-delusion, as both our diagnoses and treatments are likely guided far more by empirical observation and experience than by scientific understanding. Yet we still aim to relate observations and outcomes through the lens of biological models and basic science, so we can “make sense” of the data.
Phrased differently: while the AI approach of leveraging empirical observations to improve outcomes could well be remarkably aligned with what doctors actually do, it’s not what we think we do, and it will be hard for doctors to internalize unless there’s a way to connect the AI-based recommendations with mechanistic insight, i.e. some way to rationalize why certain inputs result in the output. Consequently, the most successful medical AI applications (at least initially) may be those that figure out how to integrate with the physician’s need to understand and to explain.
Implementing AI, Part 2: Why Pharma R&D Isn’t Biting
AI is also being used by many startups to “power” drug discovery. The core idea, echoing the Reinertsen schematic discussed above, is to use multiple subtle inputs (which can include genetics, proteomics, EHR data, imaging findings, etc.) as substrate for computation, which results (ideally) in insight relevant for drug discovery and development (disclosure: I’ve heard venture pitches in this space but to date have not made an investment). Many of these young companies aspire to use a version of phenotypic screening – which I’ve praised here – to identify and prioritize compounds, and accelerate the lengthy process of coming up with new drugs. Most such startups assert that by decreasing the failure rate and increasing the likelihood that a compound will have good properties/not have bad properties, they can radically alter the economics of drug development, and profoundly disrupt the industry.
On the strength of this promise, many AI-driven drug discovery startups have raised prodigious amounts of funding, the lion’s share of it from tech VCs; many founders matter-of-factly explain that they are seeing far higher valuations from tech VCs vs life science VCs. Why? Because life science VCs tend to value these companies in much the same way as biopharma companies evaluate acquisitions, which means, essentially, assessing the value of the lead or most promising asset. I’m not aware of any pharma acquisitions of such tech platforms in order to internalize the promoted capability to accelerate, enhance, reimagine, or disrupt the process of early drug development. Instead, pharmas generally seem to have the attitude: “Your startup claims to make attractive compounds? Great, develop an asset to the point at which it has some validation, and if we agree, we’ll partner or acquire it.”
The really interesting question is: why aren’t pharma R&D shops acquiring any of these platform companies? (Engaging in relatively de minimus partnerships that tend to garner lots of publicity – yes; but actually acquiring the startup – not that I’ve seen.) If a key problem with drug development is that the early stages take so long, yet deliver molecules that still are far more likely than not to fail, wouldn’t a platform that improved the odds be exceptionally valuable? This is presumably what the tech VC investors are banking on.
My guess is there are at several reasons why pharma companies aren’t biting (at least not yet).
First, and perhaps most intuitively, we are still in the early days. The technology may still seem long on promise and short on performance, and pharmas want to see more evidence that the tech actually works, repeatedly, before acquiring the capability.
Second, and in line with the earlier discussion of AI in medicine, I suspect drug developers are instinctively wary about acquiring what feels like a “black box” capability – “buy our platform, and an algorithm will let you know what’s most promising.” To be sure, researchers perform screens all the time, but in general, the readouts tend to be biological and discrete – increased level of a certain enzyme, for instance, or increased death of a certain type of cell. In contrast, a platform that says, “we’ll detect and integrate a lot of imperceptible signals and let you know what’s important“ doesn’t offer any sort of rationale or explanation. This premise is as difficult for drug developers to accept as it is for physicians.
A concrete distillation of this is the concept using an AI-devised classifier as a biomarker; this application can occur early in drug development, or later, at the level of patient selection for a trial. Let us focus on the latter for the sake of simplicity. If a product team wants to focus a drug on patients who express (or don’t express) a biomarker that makes mechanistic sense, we can understand it – cancer patients whose tumors express HER2, for example. But imagine if a patient selection algorithm proposes a composite biomarker that incorporates an indecipherable mix of lab chemistries, genetic variants, proteomics, and imaging. Biologically-grounded drug developers (and ultimately physicians) are likely to struggle to gain comfort around approaches that generate or rely upon mechanistically opaque classifiers. These approaches also make it difficult to apply common sense, the way a physician might attribute a high potassium level to a hemolysis artifact, rather than a medical emergency.
Third, pharma companies tend to be organized around discrete therapeutic areas – respiratory, cardiovascular, oncology, etc. Each of these areas tend to pursue their own strategies, have their own approaches for selecting and prosecuting targets, and have their own unique needs. Platforms touted as enhancing discovery, writ large, often run into the problem of each individual therapeutic area wondering what’s in it for them. In contrast, a licensed compound or biological technology that seems specifically applicable to a therapeutic area (such gene therapy for rare disease) more easily conveys value to key decision-makers.
(As an aside, I suspect this is also a key reason why, to my knowledge, the Regeneron Genetics Center – with whom I worked in a previous role — hasn’t been replicated by other companies. The Center integrates genetic and phenotypic data to identify promising targets in a fashion that’s largely agnostic of therapeutic area. This approach can be difficult to square with organizational structures built around therapeutic areas that are both clearly defined and rigorously demarcated.)
Fourth, I suspect many of these AI-driven platforms overestimate the problem-solving and de-risking they actually enable. Most drug developers believe even clever compounds born from data-driven approaches can still fail in so many more ways than the startups are likely anticipating. Or as life science VC (and fellow Forbes contributor) Bruce Booth has described, “instead of ‘software eats biotech,’ [pace Pande and Andreessen], the reality of drug discovery today is that biology consumes everything.”
Addressing specifically the concept of computer aided drug design, he writes,
“…it’s only one of many contributors to overcoming the challenges of drug discovery today. There remains a wonderful abundance of artful empiricism in the discovery of new drugs, especially around human biology, and this should be embraced.“
Finally, most pharmas are highly attuned to their priors. For all the attempts to generate promising compounds internally, an increasing number of companies have come to believe in the wisdom of “search and develop” vs traditional R&D (see here, here), a trend stretching back at least a decade. At senior levels of pharma management, there’s often a sense of fatalism around internal R&D, especially the early phases, and a corresponding disinclination to overinvest in it. Given the choice of putting a hefty sum into a disruptive flavor-of-the-month tech platform vs a tangible external compound with some evaluable data around it, most pharmas are going to choose the compound every time.
That said, pharmas are legendary fast followers. My guess is that once one major player acquires a tech platform to accelerate early R&D, every pharma CEO knows they will be grilled by the board if they don’t rapidly follow suit, and (for better or worse), many will.
My sense, so far, is that data and AI platforms are being meaningfully implemented by commercial groups, actively considered by clinical (and particularly real world evidence) groups, and beset by constant deliberation and numerous asset-focused pilots in early discovery. This implementation gradient is likely related to the relative feedback cycle time of each of these areas. You can generally figure out far more rapidly whether a commercial tweak is working than whether a research tweak is; 15% higher sales can be captured easily, but a 15% improvement in target selection can be far more difficult to assess and score – but enormously valuable if (when?) demonstrably achieved.
Concluding Thoughts
Both physicians and drug developers draw much of their authority from their ability to leverage mechanistic understanding to move from observation to insight. This ability is likely both better and worse than we typically recognize. Our mechanistic understanding is often far less robust than we appreciate, but we bring a sense of intuition and a wealth of tacit knowledge to these domains, enabling us to notice that a patient just doesn’t seem himself, or that a cell culture or chemical reaction is behaving in a curious way. Humble physicians and drug developers will seek ways to embrace (as well as critically verify) the mechanistically unmoored insights offered by ever more sophisticated algorithms. At the same time, engineers seeking to disrupt medicine and pharma would do well to temper their messianic vigor with a healthy appreciation for the lived experience and hard-won-wisdom of many incumbent practitioners.
Acknowledgement: I am grateful to Erik Reinertsen, an MD/PhD student at Emory/Georgia Tech and an intern with our team, specializing in data science, for stimulating intellectual discussion and thoughtful editorial review.
This post originally appeared in Forbes.